This is the multi-page printable view of this section. Click here to print.
Articles
Building MCP Servers the Easy Way with Apache OpenServerless
It’s 2025, and apparently, if your infrastructure isn’t running on MCP servers, are you even in tech? From stealth startups to sleepy enterprises pretending to innovate, everyone claims to be “built on MCP” — or at least wishes they were. It’s the new badge of modernity.
In this guide, I’ll show how to build an MCP-compliant server using Apache OpenServerless and our custom MCP plugin. By deploying OpenServerless and using the plugin, you can quickly expose tools via the Model Context Protocol (MCP). This setup enables fast and portable AI workflows across any cloud or on-prem environment.
The hard part about running an MCP Server
Spinning up an MCP server sounds cool and it looks easy. But the real pain doesn’t start until after the “hello world” works. Because running an MCP server isn’t the challenge — it’s keeping it running and updating it.
Want to make it available on the Internet? Prepare for a joyride through SSL, firewall configs, and reverse proxies. Thinking of scaling it? That’s when the fun begins: orchestration, autoscaling, persistence, model versioning, billing — suddenly you’re less “AI pioneer” and more “distributed systems janitor.”
This is where OpenServerless with MCP truly shines: enabling fast, portable, and secure AI tool deployment with zero DevOps, seamless orchestration, and full compliance with the Model Context Protocol.
Introducing olaris-mcp, the OpenServerless plugin to build MCP servers
We developed an Apache OpenServerless plugin, or more precisely an ops plugin for building MCP servers with Apache OpenServerless functions. A quick reminder: ops is the CLI and it supports plugins as a way to extend the CLI with new commands.
This plugin allows you to create an MCP-compliant server in a fully serverless way—by simply writing functions and publishing them to OpenServerless.
The plugin can run locally for development or be deployed to any server for production use. We support both local and public (published on the Internet) MCP servers. We will cover the latter in a future article as it enables interesting scenarios like inter-servers communications to be explored.
Note: In OpenServerless, a single MCP server consists of a number of functions, so one single MCP server is a package. It consists of a collection of tools, prompts, and resources, each represented as a distinct OpenServerless function. That means one server is always split into a number of microservices.
Installing the MCP Plugin for OpenServerless
As we said, it’s an ops plugin and can be installed directly using:
$ ops -plugin https://github.com/mastrogpt/olaris-mcp
To verify that the plugin has been installed correctly, run:
$ ops mcp
You should see the following usage synopsis (shortened):
Usage:
mcp new <package> [<description>] (--tool=<tool>|--resource=<resource>|--prompt=<prompt>|--clean=<clean>) [--redis] [--postgres] [--milvus] [--s3]
mcp run <package> [--sse]
mcp test <package> [--sample] [--norun]
mcp install [<package>] [--cursor] [--claude] [--5ire] [--uninstall]
mcp inspect <package> [--sse]
Let’s see in detail what the available commands do:
ops mcp new– Create a new MCP package tool, prompt or resource.ops mcp run– Run the specified package as an MCP server.ops mcp test– Test the generated MCP server via CLI.ops mcp inspect– Launch the MCP web inspector for the specified package.ops mcp install– Install or uninstall the MCP server locally to Cursor, Claude, or 5ire environments.
Creating a new MCP Server with a serverless function
Let’s walk through the steps to create a simple MCP server – for example, one that provides weather information for any location in the world.
We’ll start by creating a serverless function that acts as a proxy using the following command:
$ ops mcp new demomcp --tool=weather
This command initializes a new MCP package named demomcp and defines a tool called weather.
Next, you’ll need to describe your MCP tool using metadata annotations. These annotations define the tool type, description, and input parameters:
#-a mcp:type tool
#-a mcp:desc "Provides weather information for a given location"
#-a input:str "The location to retrieve weather data for"
Implementing a Weather Function
Now it’s time to implement the logic for your weather function.
You can use generative AI to get the required code quickly. For instance, the following prompt can help you generate a simple function that retrieves weather information:
AI Prompt:
A Python function get_weather(location) using requests and open-meteo.com that retrieves the given location, selects the first match, then fetches and returns the weather information for that location.
We do not include the implementation here, ChatGPT typically returns a valid and usable function.
Assuming you’ve implemented a get_weather(location) function, you can now create a wrapper to handle MCP-style invocation:
def weather(args):
inp = args.get("input", "")
if inp:
out = get_weather(inp)
else:
out = "Please provide a location to get the weather information for."
return {"output": out}
Deploy and Test the Function
You can deploy and test your MCP function as follows:
$ ops ide deploy demomcp/weather
ok: updated action demomcp/weather
$ ops invoke demomcp/weather
{
"output": "Please provide a location to get the weather information for."
}
$ ops invoke demomcp/weather input=Rome
{
"output": {
"location": "Rome, Italy",
"temperature": 26.0,
"time": "2025-06-22T06:45",
"weathercode": 2,
"winddirection": 360,
"windspeed": 2.9
}
}
$ ops invoke demomcp/weather input=NontExistingCity
{
"output": "Could not find location: NontExistingCity"
}
Testing the MCP Server
Your MCP server is now up and running, and you can test it using the graphical inspector with the following command:
$ ops mcp inspect demomcp
The Inspector connects to your MCP server, lists available tools and resources, and allows you to test their behavior interactively.
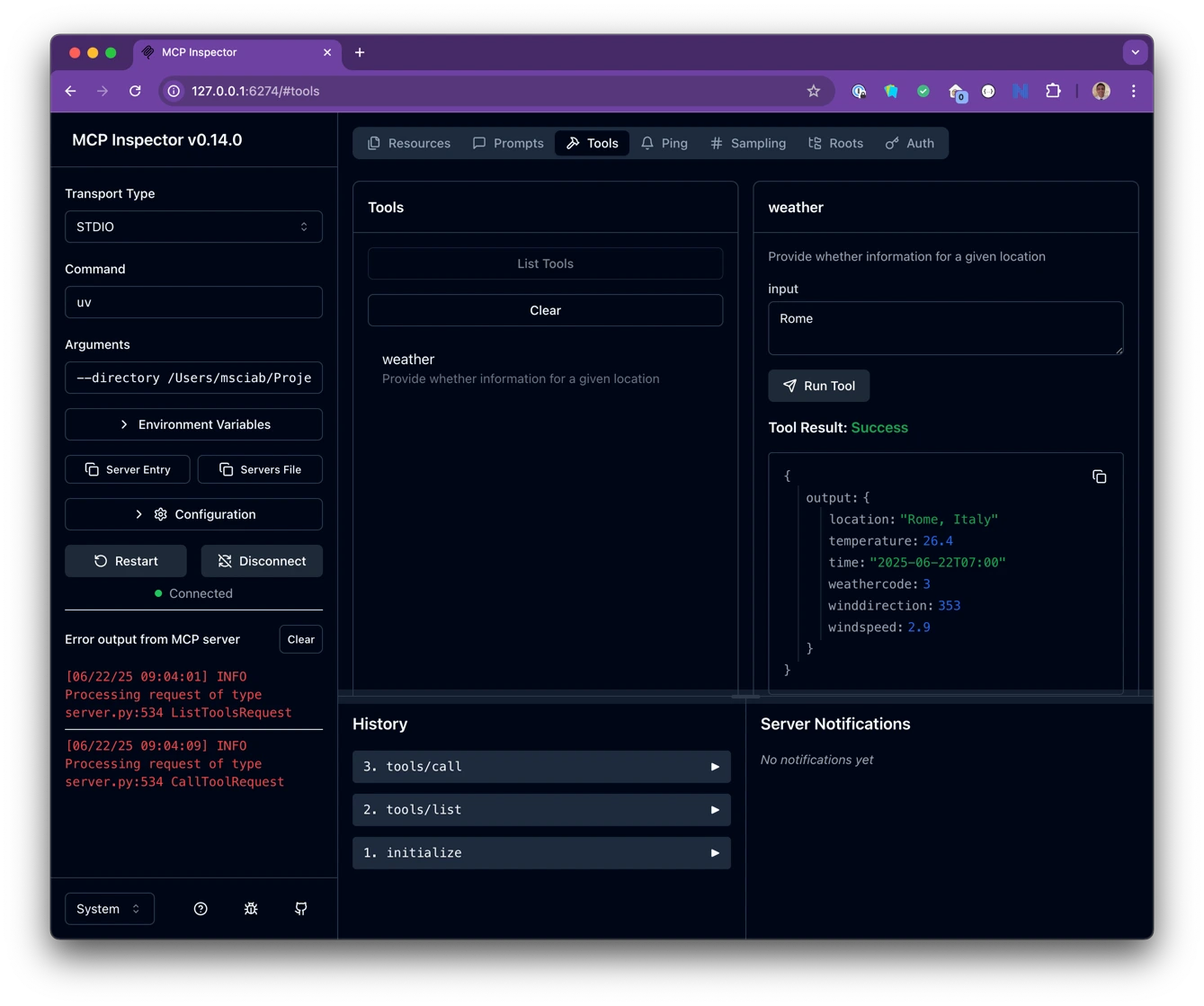
Using the MCP Server
Your MCP server is now ready to be integrated into any chat interface that supports MCP servers.
In this example, we use 5ire, a free AI assistant and MCP client that provides an excellent environment for running and testing MCP tools.
Step 1: Install the ops CLI
First, install the ops CLI. You can find installation instructions on the OpenServerless installation page.
Step 2: Add the MCP Plugin
Install the MCP plugin using:
$ ops -plugin https://github.com/mastrogpt/olaris-mcp
Step 3: Log in to Your OpenServerless Account
Use the following command to authenticate:
$ ops ide login
Step 4: Install the MCP Server into 5ire
Deploy your toolset to 5ire with:
$ ops mcp install demomcp --5ire
You’re all set! Now you can access your 5ire client and use the deployed MCP server in real conversations.
Let’s walk through how the tool works in practice:
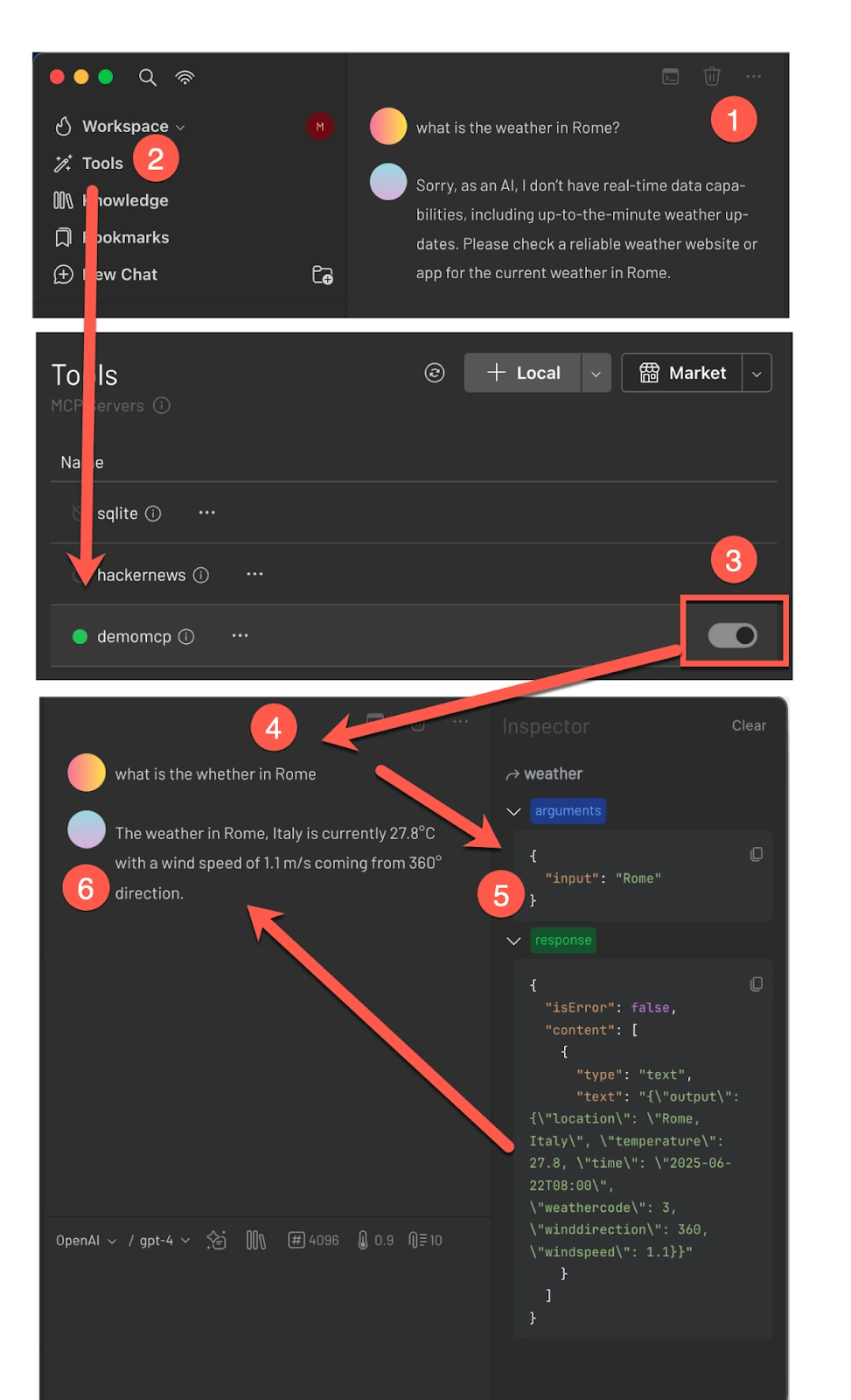
Testing it step-by-step
- Ask a Chatbot
Ask a chatbot for the weather in Rome. It will likely reply that, as a language model, it doesn’t have up-to-date weather information. - Open the Tool List
In the 5ire interface, open the list of available MCP tools. - Enable the MCP Tool
Locate your toolset (demomcp) and enable it. - Ask Again
Now that the tool is active, ask the chatbot again: “What’s the weather in Rome?” - Observe What Happens
Behind the scenes, the LLM invokes the MCP server, which triggers the serverless function that retrieves live weather data. - Success!
You’ve successfully extended your LLM to provide real-time weather information for any location in the world.
Conclusion
With Apache OpenServerless, we showed how to build and deploy a serverless MCP server in minutes, bypassing all complex system configuration.
This example covered only local MCP server configuration. However, the optimal solution utilizes public MCP servers, enabling inter-server communication via agent interaction protocols.
This is just the beginning. Public MCP servers open the door to multi-agent interactions, federation, and more.
Stay tuned for more updates from Apache OpenServerless!
Authors


Apache OpenServerless is the easiest way to build your cloud native AI application
If you have never heard of it, you may wonder: what is Apache OpenServerless? The short answer is: a portable, self-contained and complete cloud-native serverless platform, built on top of Kubernetes and especially suitable to develop production-ready AI applications with minimal effort. Because of its portability and availability in every environment, including air-gapped ones, it shines when you have strong privacy and security constraints and need to build Private AI applications.
OpenServerless embraces the functional programming paradigm, enabling developers to build modular, stateless functions ideal for scalable AI workloads: this model aligns naturally with serverless architecture and simplifies the integration of both public and private LLMs - developers can invoke proprietary APIs like OpenAI or deploy and run private models locally, ensuring full control over sensitive data. A key strength is its ability to run GPU-accelerated runtimes, allowing execution of code directly on GPUs for high-performance inference or training tasks.
The origins of Apache OpenServerless
The project Apache OpenServerless is closely related to another serverless project: Apache OpenWhisk. OpenWhisk is a portable serverless engine originally developed and open sourced by IBM, and later adopted and further developed by vendors of the calibre of Adobe, Naver, and Digital Ocean.
OpenWhisk is an excellent foundation to provide FaaS services and indeed it is adopted by many cloud providers as their serverless engine. It is also widely used in academia for research on serverless. It is highly scalable and extremely robust and reliable. However, OpenWhisk is not yet widely used because in itself is not a full platform: it is only a FaaS service and, while it is used by cloud providers, their users have little interest in making it available for wider use.
A team of contributors to OpenWhisk, working initially with the startup Nimbella (acquired by Digital Ocean), and later Nuvolaris, developed it further to make it widely accessible and more useful out-of-the-box, adding all the required components with the goal of making it a complete serverless environment. Indeed in general serverless is useful when it is coupled with storage, cache, database and frontend. Given the popularity of LLM based application development it has been also extended to fully support the development of AI applications.
The project was then donated to the Apache Software Foundation and released as Apache OpenServerless. Note in this text we sometimes omit Apache in the name, but always keep in mind that the full names of the projects are respectively Apache OpenWhisk and Apache OpenServerless, as they are both projects copyrighted by the Apache Software Foundation.
What is in Apache OpenServerless?
To clarify the difference between OpenWhisk and OpenServerless you can think in this way: if OpenWhisk were Linux, then OpenServerless would be Ubuntu. In short, it is a distribution of OpenWhisk providing a Kubernetes operator to install and manage it, a rich CLI with integrated installation and development tools and a collection of starters to build AI applications.
You can see what is in openserverless in the picture below:

As you can note at the core there is OpenWhisk, providing the scalable FaaS service, composed of a set of controllers accepting requests and queuing them in Kafka, and a set of invokers serving the requests on demand, instantiating runtimes. OpenServerless also adds a Kubernetes Operator that manages all the systems. The main purpose of the operator is to deploy OpenWhisk, but also the integrated services. At the moment there is Redis (in the open ValKey flavour), Postgresql (SQL database) and the MongoDB compatible adapter FerretDB (NoSQL), the Vector Database Milvus and an S3 object storage services. We currently support both Minio and Ceph as backends.
Also we have a special service, called streamer, designed to support SSE (server side events) commonly used with AI applications to stream answers from LLM.
The operator is actually pretty powerful as it is configurable, and allows for the creation and management of resources as it is able to create databases, buckets and redis prefixes in the environment it manages, and manage the secrets to access them.
OpenWhisk has a large set of runtimes but instead of supporting all of them, we focused and optimized the more used languages, typically Python, Javascript and PHP, and provided a rich set of libraries in order to use the integrated services.
The operator is controlled by a rich CLI, called ops. The name is a pun, a short of OPenServerless, but also Operation… and also what you say (“OoooPS!”) when you make a mistake. The CLI completes the picture as it is extremely powerful and even expandable with plugins. It manages the serverless resources as in OpenWhisk, but also includes the ability to install OpenServerless in multiple cloud providers and integrates powerful development tools. We will discuss it more in detail later.
Installation and configuration
Let’s start from the installation: you install OpenWhisk with a helm chart on a set of well known Kubernetes clusters, like Amazon EKS, IBM IKS or OpenShift v4. You need a Kubernetes cluster, that should also be configured properly. Also the installer only installs the engine and no other services.
OpenServerless CLI is more complete. It installs OpenWhisk by deploying the operator in a Kubernetes cluster and sending a configuration. But it is also able to create a suitable cluster.
Indeed the documentation explains how to prepare a Kubernetes cluster on Amazon AWS, Microsoft Azure and Google GCP using the cli called ops: there is an interactive configuration, then ops builds a suitable cluster with all the parameters in place to install OpenServerless in it.
When installing OpenServerless, you can also select which services you want to enable, and many configuration parameters that are essential. All of this just using the ops CLI to set the configuration parameters before performing the installation.
After the installation, the CLI is useful to administer the cluster, adding new users, etc. Note that each user has a complete set of services included, so you do not only create an area (called namespace) for serverless functions but also a SQL database (and a No-SQL adapter), a Vector Database, a bucket for web content (public) and another for private data, a Redis prefix (to isolate your keys in Redis).
Note that the system supports a public area for web content using a dns configuration. You need a DNS domain for an OpenServerless installation, and you usually need to point the root of the domain (@) and a wildcard (*) to a load balancer accessing it. Each user will have a different web area to upload their web content, and a mapping to their serverless functions (’/api/my’) suitable for deploying SPA applications with serverless backend support.
Development tools
So far so good, but work would not be complete without suitable development tools. You can deploy each function easily but it is a bit painful to have to deploy each function separately. Furthermore, you have to provide each function with options to change the runtime type, the memory constraints, timeouts etc. OpenWhisk supports a manifest format to do that, but does not offer other facilities for deployment.
It is still possible to use the manifest, but we also added a configuration system based on conventions: just put your code in directories and the system will automatically build and deploy.
Also, in this case, the super powers of cli ops come to our rescue! The ops development tools allow us to incrementally publish all the functions we have written, to manage their dependencies, annotations during publication; as well as publish the web part of our application. Furthermore it is possible to integrate the build scripts of our Angular, React, or Svelte application so as to be invoked during the publication process. Other useful tools allow us to handle and interact with the integrated services (Postgresql, Minio, Redis).
Conclusions and a new beginning
All of this looks interesting, but it is actually just the starting point for building AI applications, as this is our main focus. OpenServerless lays the groundwork by providing a flexible, event-driven foundation, but its real power emerges when applied to AI-centric workflows.
Our primary goal is to enable developers and data scientists to move beyond basic automation and toward complex AI systems that integrate reasoning, natural language understanding, and data processing. OpenServerless becomes a powerful platform for rapid experimentation, secure deployment, and scalable AI services. From RAG pipelines to autonomous agents, this environment is designed to evolve with the needs of modern AI, turning abstract ideas into production-ready solutions without the usual overhead of managing infrastructure or sacrificing control.
Authors